I just published a piece for DataExpert that I’m particularly proud of. Click here to read it.
Like many of my pieces, it makes a few interlapping arguments:
Data Engineers are actually product owners for data
This is particularly true in the age of AI that can do a lot of the engineering work for you
Seniority is correlated with the influence/people/non-technical parts of the job
Data systems are your product, your coworkers are your customers, you’re looking for product/market fit
Pay attention to what surfaces/numbers the principals actually use, and treat them as services that need 100% uptime (even as you gently and carefully update them)
Showmanship and reframing your work is a big (and fun) part of the job
(and more)
Plus a few different war stories from my time in the trenches.
I was spurred to write this piece years ago, when I was brought on to consult with a particularly beloved computer company. There was a lot of DE work to do, and a big question was where to start. We zoomed in on the jank google sheet company leadership was using to track numbers every day. Thinking about how to (carefully, slowly, with care) get better processes to power the “backend” of that critical artifact framed our entire plan.
I think about that a lot.
Okay, so here’s a link to the article, and later I’ll update this post with an archival copy for posterity.
I’ll paste the full text below for posterity. Some ideas in it:
Talking about an “agent” will make less and less sense. We need a new name for a “bag of agents that pretnd to be one character”. Perhaps — Entity?
There’s a race on to be the store of record (the ai scribes + filing cabinet) for business. Here’s what it’ll look like.
The real interesting part is the secretaries that manage and retrieve from that filing cabinet
Good AI secretaries have specific features that must be carefully engineered.
An overview of a working demo and vision called Lobster Talk, where different lobsters (secretaries, openclaw replacements, we don’t have a good name for them yet) coordinate in a decentralized way (and why).
And more.
Here’s the piece.
A well-architected secretary is 76 agents in a trenchcoat
Beyond “take meeting notes I’ll never read”
Hundreds of startups (and maybe an internal team at your company) are trying, right now, to build and sell you on an army of AI scribes. That’s fine, and it’ll be useful. But what you’ll really need are competent, trusted, proactive secretaries. That’s much harder. But doable!
AI has evolved into new UX patterns. This will continue.
So, we have robots (LLMs, agents, whatever you want to call them) now. What can we use them for?
Well, robots have changed their shape over the last few years. We went through these affordances:
GPT playground (autocomplete)
ChatGPT (chatbot)
custom (RAG) setups (understand your files specifically)
Each was useful! Businesses are being built on them.
So — what next? And what can we learn?
Well, we’re about to see a new layer – the army of scribes. You’ll be tempted to use them directly. You’ll then be tempted to hook them up to your robot assistant. Fine. But the real action will be in giving that assistant enough context, power, and team-aware-capabilities so that it can actually be a useful clerk or secretary.
And it’ll be fine! It’ll be useful. But how often do you currently read meeting notes? How will it feel, really, to have action items more efficiently thrown your way? You’re still tied to the tyranny of staring at a screen and typing on a keyboard.
What’s more interesting is what will happen next.
We can do better than delegating notes to robots
Think about depictions of principals doing magnificent work across media.
How will it feel, really, to have action items more efficiently thrown your way? You’re still tied to the tyranny of staring at screen and typing on a keyboard
What do these people have in common? They have fun, creative jobs. They have meetings. They have big thoughts. They made decisions. They do not slave over a typewriter or word document. They do not take meticulous notes. They have staff for that. (Notably, being the staff is generally a lot less pleasant.2)
In the near future – that could be you. But if you want that life, you need staff to do the less fun work. Beyond just scribes taking notes. You need clerks. You need secretaries. And you need them to be as reliable and competent as those fantasy secretaries. But since they’re robots, you don’t actually need to worry about whether their jobs are rewarding.
But what do real-life secretaries actually do?
Well, in large part, you’re currently a secretary to yourself. Modern real-world workplaces spend a lot less money on logistical support than fantasy TV offices do. You do a lot of typing. You send memos. You route information between people on your team. You update documentation. You schedule and bargain and procure. You might communicate with vendors and outsiders or do other logistics. You type. You do it all in the background as part of supporting your “real” work. It may feel tactically rote, but it relies on a wealth of knowledge and trust and context that you can’t hand off cleanly – at least, until now.
What do secretaries actually do? Well, in large part, you’re currently a secretary to yourself.
Now what does this look like in our near-future?
Mostly-reliable scribes are a commodity
Your company will set up scribes. You will have an invisible system of robots doing certain menial tasks. Your conversations will be filed, your notes will be taken. The notes will be parsed into decisions. Jira tickets will be filed and closed. Executives will get daily summaries of what their teams are up to. Action items will be filed after each meeting.
This might even be built, in a half-baked way, in your team right now.
That’s the basic, obvious vision. Robots swarm around writing notes, reading notes, answering your questions about your notes. An army of scribes writing into a giant filing cabinet.
Importantly – you’ll need these scribes to be so good that you don’t spend a lot of time fixing their filing mistakes. Or, more interestingly, you’ll need some other entity to make sure they got it right.
(”So far, so good! But weren’t we talking about secretaries?” — yes, shh. We’re going deeper).
SIDEBAR: What about OpenClaw?
There’s an obvious reaction to all this: “hey, isn’t this just openclaw? OpenClaw/Hermes/IronClaw is already my personal assistant”. Well, kinda. Not really. The first prototypes of AI secretaries we see will likely be built on a foundation of *claws, but we need AI systems that have these core design principles:
Built for teams (of humans and similar robots) from the ground up.
Coordinating across systems of code, people, and other AIs (invisibly, constantly)
Will integrate with company systems (and be trusted by IT not to leak or delete everything)
Likely multi-server and multi-model.
Opinionated on what happens invisibly/continuously and need user approval or visibility.
And more (see below).
This will require a new and different type of architecture than looping agents on a server and connecting it to Telegram.
A scribe writes things down. A secretary proactively preps.
But wait. A beautifully organized filing system doesn’t work well unless you can use it; at the same time you don’t want to access it yourself. Otherwise you’re back in the drudgery of paperwork.
And you need to be able to give orders — often implicitly phrased as “if X, then Y”. (Current tooling is pretty bad at this right now)
You need someone to proactively and reactively hand you the perfect manila folder each time you need it.
And, suddenly, we’re not talking about a scribe at all. We’re discussing something more interesting. The layer on top of that. The secretary. A clerk that talks to the invisible army of scribes on your behalf, sure, but so much more than that. It must continuously manage attention, context, information, and execution across time.
Let’s go further. You’re at work.
When you go to a meeting with someone else on your team, you want your secretary to know ahead of time, talk to their secretary, compare notes, write briefing docs for the meeting, hand them to you on a just-in-time basis (or maybe send you the pre-read in the morning and the prep doc 10 minutes ahead of the meeting) — AND understand any decisions you make in the meeting and implement them.
When you work on an architecture plan, you want your clerk to interrupt you, and tell you that team ABC tried something similar in the company 2 years ago.
The clerk has:
Simple retrieval: Pulled all the notes
Social graph querying with sophisticated privacy / sensitivity features: Talked the clerk of the Albert, the lead architect of ABC, and got from them the sensitive learnings that weren’t in the official document.
(“Joe is great at code but horrible at explaining things well – we should not have made him a project lead on this”, “direction X was really promising but couldn’t pursue it due to office politics”, “I’ve subsequently learned about Y pattern that we should have used instead”)
Followed up with the clerks of Joe, Sally, and Martha who were also on that project.
Negotiation with other clerks: Booked coffee with Albert, who will be in town next week (but does not show his free time on his calendar)
Proactive pushing of info: Prepped Albert’s clerk with all your context
Context aware synthesis: Written you a report on what, from project ABC, can you actually learn
That’s a vision. Maybe a compelling vision. It is to me.
Suddenly, we’re not talking about a scribe at all. We’re discussing something more interesting. The layer on top of that. The secretary.
And I think we can build it.
Can you trust your robot secretary?
For all this to work, you need reliability, trust, and even discretion.
You need to know that stuff won’t get dropped. Dropped is terrible. Forgotten about? Also terrible, but as long as it is filed somewhere you can recover.
You need to be able to fire your secretary. In this case, that means that if you stop using your particular AI system, porting to a new system needs to be incredibly easy. The secretary’s notes need to play well with the filing/scribe system the company uses. It needs to be flexible enough to take a filing system as it exists and invisibly clean it up to its standard over time.
Some robots need to know about the existence of, say, an email or meeting (”the boss is meeting a lawyer to talk about his divorce”) but NEVER leak the content of it. And we need to trust that they never double-book, and might even do polite fictions if necessary.
SIDEBAR: Your secretary is many agents in a trenchcoat
Note that I’m not using the word “agent” a lot here. That’s because your clerk, secretary, even your scribe – they’re not going to be one agent. Why should they?
An agent is analogous to a process on a machine. Processes can fork, or call other processes. They can die without implicating each other. A traditional “program” on your laptop has many processes running at once. But a SASS app has so many different computers involved that talking about processes feels like you’re missing the point.
So too with anthropomorphized robot helpers. Maybe on one server there’s a dispatcher agent that calls research agents, runs async scripts, negotiates with the company data layer. Maybe it coordinates with a dispatcher on another server that message and info passes with other assistants. A third dispatcher on a third server might be the layer that talks to you (and also runs subagents for odd jobs rather than message passing to the other two).
I’m not saying this is a good architecture, by the way. But it’s entirely feasible. And, to my point: who is the “agent” you’re talking to in this scenario? Even “Multi-agent system” is too low-level. We don’t quite have the right words the emerging thing we’re describing. Agent OS? AI persona?
I have some thoughts on how to build it. I’ve even started. The keys, so far, seem to be:
Start from an assumption that your secretary is working on a team
Set up the right dispersion of deterministic and LLM control flow
Use a really rich schema for how secretaries communicate in structured ways.
Some primitives that I’ve found useful:
Dispatcher/subagent structure
Code. Gatekeepers, hooks, a message queue, and injection of prompts to deterministically both nudge and enforce behavior.
Rich schema for discretion, communication, decisions, and memories.
Secure enclaves of local LLMs that monitor the frontier model “kernel” and gatekeep its communication for the correct discretion sensitivity.
Federated CRMs and knowledge graphs within a team
An “If this, then that” data structure that points to the right memory when agents match a certain behavior (solving the “remember to look up a memory telling you to remember something problem).
Logs and health check monitors everywhere
But the crux, maybe, is this: the world of OpenClaw clones is running into two bottlenecks: security/privacy/reliability, and the need for an actual killer app. Those are related. Imagine a world where everyone has some sort of robot butler — but their *claws talk to each other well. Invisibly, carefully.
SIDEBAR: Clerks and Secretaries and CoS
Why “secretary”? Why not just “clerk?” Well, the term clerk doesn’t quite bring up the level of familiarity and trust that I’m going for. Does a clerk know about your sensitive meeting even as they don’t put it on the calendar? Clerks are closer to paper pushers than autonomous agents.
Another word you could use was “chief of staff”. But that has its own limitations – mostly the term means very different things. The CoS in a government agency basically runs it. A CoS in tech has extremely different responsibilities than one in nonprofits. And so on.
So, when using “secretary”, I’m trying to evoke a level of trust, competence, autonomy and brilliance that we see in a Joan or Peggy. Without anyone involved being as poor a boss or bad a person as a Don Draper.
Against communication explosion
That’s the future I see. We shouldn’t just throw our robots into Slack3 and call it a day. You don’t teach students by throwing them all into a gym and having them run around yelling at each other. You don’t run a company by having CEOs spying on how each worker is sending notes to each other.
We will have our AIs morph betweencopilot and HUD. They’ll share information in a smart way. They’ll know they’re on a team and work accordingly.
So don’t obsess over the coming scribes. That’s tomorrow’s tech. Build assuming that it exists. Focus on using it in smart ways rather than staying stuck as your own secretary.
The interesting part of it is how. Which framing will resonate with your company? Which strategy to integrate to your company will actually succeed? (I think the jargon for this is “change management”. ) ↩︎
Some of these very shows — Mad Men and Ted Lasso, for example — put a lot of narrative weight into underscoring the importance and brilliance of these support staff and what happens when the relationship gets sour. ↩︎
Some of these very shows — Mad Men and Ted Lasso, for example — put a lot of narrative weight into underscoring the importance and brilliance of these support staff and what happens when the relationship gets sour. ↩︎
The other day some form or another asked: “what is your baby’s personality?”. Sarah and I looked at each other, a bit bemused. Does Omri have one yet? How can you tell the difference between something real and just “generic baby”?
We talked it out, and here’s our list (as of a few months ago). As you can see, it’s a pretty big list. I guess he’s got a unique personality after all!
The first things we came up with:
Cheerful.
Calm around new people.
Loves being the center of attention; he even enjoys going to the doctor because at the office, it’s all about HIM
Passionate about objects — in both directions. He will flip from YES to no on the turn of a dime.
Strongly believes that he should be held; strongly believes that people should hang out with him.
Petulant and strong willed about food and sleep. These are the two exceptions to his general chill pattern of behavior.
Curious about the world, especially objects.
Loves holding things, especially things that are “sticks” — long and graspable.
Does not believe in moving much. Would rather be sedentary and held.
Delights in games. And anything can be a game. If you approach any sort of thing (wiping his face, cleaning him, bopping him on the head, whatever) as if you’re playing together, he’s willing and ready to believe it and be excited to join in.
Smiles easily.
Doesn’t cry unless there’s a reason. The reason is often: “I don’t want to go to sleep. I feel comfortable here, don’t leave the room. I want to play with you, I don’t want to sit on the floor.”
Moderately indifferent to temperature.
Does NOT want to lie on his stomach. will flip over immediately.
Fascinated by electronics. Yes, fisher-price objects, but also anything with a screen
Wants to smash his fingers on keyboards especially.
Loves mirrors, as well as video chats (since he can see himself)
On some more reflection:
Has been known to try to feed others, especially his parents. (Adorable.)
When crying and hungry, sometimes too angry to actually eat.
Tries to make eye contact with everyone.
New things (and beloved things) go Straight To The Mouth™
Desires things that adults pay attention to — phones, airpods, keyboards. If there’s a toy with a motor, he wants to figure out the parts that move. Will grab them, examine them, etc. That’s more important than playing with the e.g. duck the way he’s supposed to.
Does not dislike bathtime.
Our special songs will make him sleepy on cue.
Wants to turn the pages of books — often wants to turn the book straight to the beginning or end. Hard to focus and go through it calmly
Will eat paper. Beware.
Mouth turns into a letterbox right before crying
These seem to be especially true of him specifically, or generally interesting
Demands to drink water from a glass or cup
Will flick water by pulling back on his straw and letting go
(Then gets sad and surprised when he splashed himself with it)
Fascinated by water in general. The dishwasher is his television
Will smash his legs up and down when sleepy.
Breakdances in the crib.
Glasses, mugs, cups — he both wants to drink from them and generally hold them
Smart enough to rip clothes, towels, etc off his head. Has object permanence
Flaps his arms up and down when excited. Including in the sleep sack.
Rubs his spoon (favorite toy) on his head a lot.
Will respond happily if you talk to him in baby language. Especially if you use some of his signature phrases: Gagagagaga, thbbbt, adadada, aga, ha ha ha.
Will laugh if you say Ha Ha Ha in the right way.
Back to generic baby things?
Wants to put his fingers in everyone’s mouth
Whacks his spoon into bottles when drinking milk
Enjoys breast milk more than formula. A real connoisseur
Fascinated by posters. wants to rip them off the wall
Will bang whatever object in his hands (spoon, lotion bottle, rattle, whatever) against the wall and get excited about the noise it makes
Generally uses his index finger to poke and examine things
Shocked and sad when sneezing productively
Does not like tissues, would rather wipe his hands with his nose
Generally dislikes lying down. Would much rather change while sitting than lying down.
Hey! Did you know I have at least one other blog? sahar.substack.com. Unclear how they’ll differ, but now it seems to be that it’s the more public/professional one (fewer mixtapes for Sarah, more thinkpieces).
So, I wrote a piece over there — Will AI chatbots be compromised like CNN, or compromised like Facebook?It’s about the ethical pressures that institutions/politics/governments put on companies. Mapping out how that played for journalism, for social media, and predicting how it might look for AI chatbots. Would love your thoughts on it. Thanks.
And here it is, pasted for posterity:
Social media went bad. Pressure from hostile governments contorted the product. Lies, slop, and propaganda. Scams, spam, and doomscroll content. The list goes on.
But — this is not humanity’s first rodeo. We’ve had big companies before. We’ve had big communications companies before. We’ve had international companies before. We’ve had competitive pressures and races to the bottom before. So what was new and scary about social media?
In my view, it was this: the combination of: communications company, international reach, and editorial decisions being embedded in software processes was new, and open to abuse. (Gee, what else fits that category?)
These companies are vulnerable to pressure from rogue governments, advertisers, or media demagogues. And the consequences of that are uniquely far-reaching.
International companies have run into pressure from the governments of other countries before. And honestly, they’ve been more directly evil than anything alleged about social media companies. Even Elon Musk’s Twitter doesn’t arm death squads. Meta has not poisoned tens of thousands of people to death in one night1. No tech company, to my knowledge, has bribed a military to massacre protestors they don’t like.2
To put it a bit bluntly — if Coca Cola did a bad thing because a government demanded bribes or whatever, that sucks for the residents of that country, but not the whole world.
Social media corruption hits different, for a few reasons. Some small, and one big.
The small reasons:
Social media is not seen as “journalism” with the norms and protections that implies. It’s easier, culturally, to get away with bad behavior.
No firewall between business and editorial that journalism has.
It’s a concentrated point of failure: there are only a few giant social media companies. Each is a bigger target for influence, and there’s less chance that other competitors will outcompete them on “resistance to censorship by foreign dictatorships”
The big reason:
When kowtowing to outside pressure, social media companies don’t just take down posts or even accounts or pages. They change the ranking systems of the product at scale to satisfy outside pressure.
That means that every time Meta scuppers plans to add a new anti-spam downrank because of backlash from Narendra Modithe whole world suffers from that lack of protection.
So things that would be the normal “soft” corruption in American business: preferential treatment for big clients, a hesitance to make big changes without seeing their impact on existing customers, an instinct to fold when attacked by a particular political party — are much worse here.
Compromises and tweaks to satisfy unjust power are no longer localized to one story or country — everywhere in the world gets the summation of all the downgraded protections from everywhere else.
This is really quite scary. And it’s unlike anything else I can think of — outside of tech.
Right now, people are indeed worried about “AI Bias”. (And, frankly, there are compellingreasons to be worried!) But — it’s inchoate. Firms are moving quickly, companies are new and comparatively lightly staffed, and the products change day to day. Things will change.
In the future, there will still be flashy fights about “<political party> thinks that <X AI product> is biased against them”. But more quietly, governments, political figures, firms, etc will threaten, behind the scenes. They’ll extract concessions. And we will be none the wiser.
So, that’s not great. But! I think the bad results will look more like Bloomberg form than the Facebook one. For two structural reasons.
First: AI companies are stronger than social media companies
Social media companies are weak.Especially Meta. The company isn’t popular. It is structurally vulnerable to pressure. It buckles easily. Social products generally have been moving away from wholesome in their brand positioning (friends!) to something odder. Maybe more like … necessary? (If you don’t watch our tiktoks you will be out of the loop and culturally isolated)
AI companies might be structurally stronger. They are newer and less tarnished consumer brands. They have a direct connection to the user, and direct moral ownership of content.5 Their value add is, in part, the quality of their responses, so monkeying with those responses for reasons beyond quality and usefulness is a direct hit to their brand and positioning.
Plus — their product is simpler to understand
Imagine that a social network updates their ranking system to steer people away from websites festooned with malware. Media demagogue X notices their weekly traffic declined by 20% and demands that it be rolled back. But normal people (and the press! and regulators!) would find it hard to detect either the change or the rollback. Meanwhile, imagine that a frontier lab updates their model, and in the course of many changes, the bot becomes more factual about a contentious event in the past. The change would be visible to everyone — but a demagogue would be hard pressed to demand the entire model refresh be undone.
AI chat companies are seen as much more responsible for what their models output, so they have less plausible wriggle room to say: we’re not debasing ourselves by censoring content a billionaire doesn’t like, we’re only changing some ranking weights.
AI can be lobotomized cleanly. (And that’s better than the alternative)
For social media — ranking rules are generally global, and apply to content from entities. So the pressure from the outside looks like “across the world, give more reach to these accounts / give less reach to content that looks like X”. Content is indeed banned or downranked — but entire algorithmic changes are also up for grabs. For chatbots, facts are the relevant objects to be tinkered with. Neural networks don’t (yet?) have an easy “these are the communist party officials you must boost content from” lever.
So rather than “Tucker Carlson will denounce the company on air unless you turn off your anti-spam protections” you get “Tucker Carlson will denounce the company on air unless you stop your model from talking about Bubba the Love Sponge”. Which, I think is better?
Topic-specific censorship is visible, testable, and contained. Whereas systemic corruption can be invisible, pervasive, and ruining much more than a few topics. As a user, I can route around known blind spots or obsessions an AI has, but subtle bias — much harder.6
This isn’t a super hopeful vision of the future. Our shared informational commons getting poisoned by determined intelligence agencies isn’t great! I guess what I’m saying is — it is better to have a model lobotomized about Tiananmen Square specifically than a model systematically pushing CCP propaganda broadly.
And then execute others after a show trial? Yikes, Royal Dutch Shell. Eeek. ↩︎
I gotta say, researching the links for this piece hit hard. I did not know about this scandal before today. Wow. ↩︎
For now, I’ll focus on chatbots because they’re the most consumer-focused use case, but of course there’s a lot more to LLMs than chatbots ↩︎
The greatest trick social media ever pulled was grabbing the credit for the good posts and deflecting blame for all the bad ones. Chatbots get all the credit, good and bad, for their outputs. ↩︎
Let’s talk about the pain of unlearning and then let’s get to the magic.
Imagine you’re an analyst at a social media company. The retention team asks: “For users who now have 1000+ followers but had under 200 three months ago – what device were they primarily using back then? And of the posts they viewed during that growth period, how many were from accounts that were mutuals at the time?”
You need to join user data (follower counts then and now), device data (primary device then and now), relationships (who was a mutual then vs now), and post views – all as of 3 months ago.
With most data warehouse setups, this query is somewhere between “nightmare” and “impossible.”
You’re dealing with state, not actions. State in the past, across multiple tables. There’s a word for this problem – slowly changing dimensions. Whole chapters of textbooks deal with various approaches. You could try logs (if you logged the right stuff). You could try slowly changing dimensions with `valid_from/valid_to` dates. You could try separate history tables. All of these approaches are painful, error-prone, and make backfilling a living hell.
There’s a better way. Through the magic of ✨datestamps✨ and idempotent pipelines, this query becomes straightforward. And backfills? They become a button you push.
Part 1 fixed weird columns, janky tables, and trusting your SQL. Part 3 will cover scaling your team and warehouse. But now – now we fix: backfills, 3am alerts, time complexity, data recovery, and historical queries.1
The old way was a mess
Here’s what most teams do when they start out:
Option 1: Overwrite everything daily
Your pipeline runs every night, updates dim_users with today’s snapshot, overwrites yesterday’s data. Simple! Until six months later when someone asks “how many followers did users have in March?” and you realize: that data is gone. You have no history. You can’t answer the question. Oops.
(Jargon alert – Apparently this is SCD Type-1 ¯\_(ツ)_/¯ )
Option 2: Try to track history manually
Okay, you think, let’s be smarter. Add an updated_at column. Or maybe valid_from and valid_to dates, with an is_current flag. When a user’s follower count changes, don’t update their row – instead, mark the old row as outdated and insert a new one.
Your pipelines need custom logic to “close out” old rows before inserting new ones
If you mess up the valid_to dates, you get gaps or overlaps in history
Backfilling becomes a nightmare – you can’t just rerun a pipeline, you need to carefully update dates without breaking everything downstream
Querying becomes a nightmare. To get user data “as of 3 months ago”, you need:
SELECT * FROM dim_users WHERE user_id = 123 AND valid_from <= ‘2024-10-01’ AND (valid_to > ‘2024-10-01’ OR valid_to IS NULL)
Now imagine joining MULTIPLE historical tables (users, devices, relationships). Every join needs that BETWEEN logic. Miss one and your results are silently wrong. Get the date math slightly off and you’re joining snapshots from different points in time. Good luck debugging that.
Option 3: Separate current and history tables
Some teams maintain dim_users (current snapshot) and dim_users_history (everything else). Now you’ve got two sources of truth to keep in sync. Analysts need to remember which table to query. Any analysis spanning current and historical data requires stitching across tables with UNION ALL. It’s a mess.
And, depending on how the dim_users_history table works – it won’t solve any of the problems you’d have in option 2!
All of these approaches share a problem: they’re trying to be clever about storage. They made sense when disk was expensive. They don’t anymore.
(Jargon alert – This is SCD Type-4. Note that I didn’t know this when I started writing this blog post because it’s useless, boring, outdated jargon. Ignore it.)
There are other SCD types beyond these, you can find an in-depth video on them here
The new way: Just append everything
You solve it with date stamps. You solve it with “functional data engineering”.
What you really want is a sort of table that tracks state – a dimension table –, but where you can access a version that tracks information about the world today, and another version that tracks information about the world in the past.
Maxime Beauchemin wrote the seminal public work on the idea here. But, honestly, I think the concept can be explained more plainly and directly. So here we are.
The thinking goes like this:
We’re getting new data all the time.
Let’s simplify it and say – we get new data every day. We copy over snapshots from our production database each evening.
There are complex, convoluted ways to keep track of what data is new and useful, and what data is a duplicate of yesterday.
But wait. Storage is cheap. Compute is cheap. Pipelines can run jobs for us while we sleep.
It’s annoying to have a table with the data we need as of right now, and either some specialized columns or tables to track history..
Instead, what if we just kept adding data to existing tables? Add a column for “date this information was true” to keep track.
Here’s what it looks like in practice. Instead of overwriting your dimension tables every day, you append to them:
Now that impossible retention query becomes straightforward. No BETWEEN clauses, no valid_from/valid_to logic – just filter each table to the date you want:
-- For fast-growing users, what device did they use back then?
WITH
today_users as (SELECT user_id, followers as today_followers
FROM dim_users WHERE ds = ‘2025-01-16’ AND followers >= 1000),
past_users as (SELECT user_id, followers as past_followers
FROM dim_users WHERE ds = ‘2024-10-01’ AND followers < 200),
past_device as (SELECT user_id, device
FROM dim_devices WHERE ds = ‘2024-10-01’),
user_device as (
SELECT tu.user_id, today_followers, past_followers, pd.device
FROM past_users pu
JOIN today_users tu ON pu.user_id = tu.user_id
JOIN past_device pd ON tu.user_id = pd.user_id),
views as (
SELECT post_id, viewer_id, poster_id, ds
FROM fct_post_views
WHERE ds BETWEEN ‘2024-10-01’ AND ‘2025-01-16’)
SELECT
ud.user_id,
ud.device as device_during_growth,
COUNT(DISTINCT views.post_id) as posts_from_mutuals
FROM user_device ud
LEFT JOIN views
ON ud.user_id = views.viewer_id
LEFT JOIN dim_relationships past_rels
ON views.viewer_id = past_rels.user_id
AND views.poster_id = past_rels.friend_id
AND views.ds = past_rels.ds -- mutual status AS OF view date
AND past_rels.is_mutual = true
GROUP BY 1, 2
Is this query complex? Sure.2 But the complexity is in the business logic (what you’re trying to measure), not in fighting with valid_from/valid_to dates. Each query just filters to ds = {the date I want}. That’s it.
The idea is that you’re not overwriting existing tables. You are appending.3
Sidebar: Common Table Expressions
If I had a SECOND “one weird trick” for data engineering, CTEs would be it. CTEs are just fucking fantastic. With liberal use of common table expressions (the WITH clause you saw in the retention query above), you can treat subqueries like variables – and then manipulating data feels more like code. Make sure your query engine (like Presto/Trino) flattens them for free – but if it does: wowee! SQL just got dirt simple. (a free one hour course on CTEs here)
When you grab data into your warehouse4, append a special column. That column is usually called “ds” – probably short for datestamp. You want something small and unobtrusive. (Notice that “date” would be a bad name – because you’d confuse people between this (date of ingestion of data) and the more obvious sort of date – date the action happened.) For snapshots, copy over the entire data of the snapshot, and have your “ds” column be <today’s date>. For logs, you can just grab the logs since yesterday, and set the ds column to <today’s date>.
Sidebar: Date stamps vs Date partitions I’ll mostly say “date stamps” in this piece – the concept of marking each row with when that data was valid/ingested.
“Date partitions” is how most warehouse tools *implement* date stamps. A partition is how your warehouse physically organizes data. Think of it like: all rows with ds=2025-01-15 get grouped together in one chunk, ds=2025-01-16 in another chunk, and so on. (In older systems, each partition was literally a separate folder. Modern cloud warehouses abstract this, but the concept remains.)
Why does this matter? When you query `WHERE ds=’2025-01-15`, your warehouse only scans that one partition instead of the entire table. This makes queries faster and cheaper (especially in cloud warehouses where you pay per data scanned).
People use the terms interchangeably. The important thing is the concept: tables with a date column that lets you query any point in history.
Every table emanating from your input tables should add a filter (WHERE ds={today}), and similarly append the data to the table (WHERE ds={today}). (Except special circumstances where a pipeline might want to look into the past).
That’s it! Now your naive setup (overwriting everything every day) has only changed a bit (append everything each day, and keep track of what you appended when) – but everything has become so much nicer.
This is huge
This has two major implications:
First, many types of analysis become much easier. Want to know about the state of the world yesterday? Filter with WHERE ds = {yesterday}. Need data from a month ago? Filter with WHERE ds = {a month ago}. You can even mix and match – comparing today’s data with historical data, all within simple queries.
Second, data engineering becomes both easier and much less error prone. You can rerun jobs, create tables with historical data, and fix bugs in the past. Your pipeline will produce consistent, fast, reliable results consistently
What “functional” actually means
(Aka “I don’t know what idempotent means and at this point I’m afraid to ask”)
So, in Maxime’s article (link) there’s all this talk about “functional data engineering”. What does that even mean? Let’s discuss.
First, we’re borrowing an idea from traditional programming. “Functional programs” (or functions) meet certain conditions:
If you give it the same input, you get the same output. Every time.
State doesn’t change. Your inputs won’t change, hidden variables won’t change. It’s clean. (AKA “no side effects”)
Okay, so what does that mean for pipelines? Functional pipelines:
Given the same input, will give the same output
Don’t use (or rely on) magic secret variables
This is what people mean when they say “idempotent” pipelines or “reproducible” data.
And here’s how to implement it: datestamps.
Your rawest/most upstream data should never be deleted – just keep appending with datestamps
Pipelines work the same in backfill mode vs normal daily runs
If you find bugs, fix the pipeline and rerun – the corrected data overwrites the bad data
Time travel is built in – just filter to any ds you need
Datestamps also give you the nice side-effect of having it be very clear how fresh the data you’re looking at is. If the latest datestamp on your table is from a week ago — it’s instantly understandable not only what’s wrong, but also you have hints about why.
Sidebar – what this looks like in practice: Your SQL will look something like: WHERE ds=’{{ ds }}’ (Airflow’s templating syntax)or WHERE ds=@run_date (parameter binding).
Your orchestrator injects the date – whether it’s today’s scheduled run or a backfill from three months ago. Same SQL, different parameter. That’s the whole trick.
Backfilling is now easy, simple, magical
Remember that retention query? Now imagine you built that analysis pipeline three months ago, but you just discovered a bug in your dim_relationships table. The is_mutual flag was wrong for two weeks in November. You fixed the bug going forward, but now all your retention metrics from that period are wrong.
With the old SCD Type-2 approach, you’re in hell:
You can’t just “rerun November.” Because each day’s pipeline depended on the previous day’s state. Day 15 updated rows from Day 14, which updated rows from Day 13, and so on. To fix November 15th, you’d need to:
Rerun November 1st (building from October 31st’s state)
Wait for it to finish
Rerun November 2nd (building from your new November 1st)
Wait for it to finish
Rerun November 3rd…
…keep going for 30 days, sequentially, one at a time
And this is assuming nothing breaks along the way. If Day 18 fails? Start over. Need to fix December too? Add another 31 sequential runs.
Now imagine instead of backfilling six days of data, you’re backfilling 5 years. This goes from being 6 times faster to hundreds and hundreds of times faster (depending on your DAG’s concurrency limits)
In Airflow terms, this is what depends_on_past=True does to you. Each day is blocked until the previous day completes. Backfilling becomes painfully slow. But that’s by no means the worst part.
You can’t just hit “backfill” and walk away. Your normal daily pipeline logic doesn’t work for backfills. Why? Because SCD Type-2 requires you to:
Close out existing rows (set their valid_to date)
Insert new rows (with new valid_from dates)
Update is_current flags
Handle the case where a row changed multiple times during your backfill period
Your daily pipeline probably has logic like:
-- Daily SCD Type-2 pipeline (simplified)
-- Step 1: Close out changed rows
UPDATE dim_users
SET valid_to = CURRENT_DATE - 1, is_current = false
WHERE user_id IN (
SELECT user_id FROM users_source_today
WHERE <something changed>
)
AND is_current = true;
-- Step 2: Insert new versions
INSERT INTO dim_users (user_id, followers, valid_from, valid_to, is_current)
SELECT user_id, followers, CURRENT_DATE, NULL, true
FROM users_source_today;
This works fine when you’re processing “today.” But for a backfill? You need different SQL:
You need to carefully reconstruct valid_from/valid_to for historical dates
And handle the fact that a user might have changed multiple times during your backfill window
This gets messy fast.
You’re essentially rewriting your pipeline. (WHY?)
So now you’re not just waiting 30 sequential days – you’re maintaining two separate codebases: one for daily runs, one for backfills. And every time you change your daily logic, you need to update your backfill logic to match. More code to write, more code to test, more places for bugs to hide. It’s completely useless and unnecessary.
Sidenote – even worse, if you’re outside your retention window (say, the source data from 90 days ago has been deleted), you can’t backfill at all. You’d need to completely rebuild the entire table from scratch, from whatever historical snapshots you still have. Which probably means… datestamped snapshots anyway. Womp womp.
With datestamps, backfilling is trivial:
Your pipeline for any given day just needs:
Input tables filtered to ds=’2024-11-15’ (or whatever day you’re processing)
Write output to ds=’2024-11-15’
That’s it. November 15th doesn’t need November 14th. It just needs the snapshot from November 15th.
All 30 days kick off in parallel (up to your concurrency limits)
Each day independently reads from its ds partition
Each day independently writes to its ds partition
No coordination needed between days
The whole month finishes in the time it takes to run one day
The exact same SQL that runs daily also handles backfills – no special logic, no custom code
This changes everything:
No more custom SQL for backfills – It’s just a button you push. Your orchestrator handles it. The same pipeline code that runs daily also handles backfills. No special logic needed.
New tables get history for free – Created a new dim_users_enriched table today but want to populate it with the last year of data? Just backfill 365 days. Since your input tables have datestamps, the data is sitting there waiting.
Bugs in old data become fixable – Fix your pipeline logic, backfill the affected date range, done. The old (wrong) data gets overwritten with the new (correct) data for those specific partitions. Everything downstream can reprocess automatically.
Upstream changes cascade easily – Fixed a bug in dim_users? All downstream tables that depend on it can backfill the affected dates in parallel. The whole warehouse stays in sync.
This is possible because your pipelines are idempotent. Run them once, run them a thousand times – given the same input date, you get the same output. No hidden state, no “current” vs “historical” logic, no manual date math.
One pattern to avoid: Tasks that depend on the previous day’s partition of their own table. If computing today’s dim_users requires yesterday’s dim_users, you’ve created a chain – backfilling 90 days means 90 sequential runs that can’t be parallelized. This is sometimes necessary for cumulative metrics, but most dimension tables don’t need it – just recompute from raw sources each day.
For most datestamped pipelines, depends_on_past should be False. Each day is independent – the only dependency is “does the upstream data exist for this ds?”
Welcome to the magic of easy DE work
We started this article staring at the prospect of valid_from/valid_to logic, sequential backfills that take days, and custom SQL for every backfill and cascading for every bugfix. Yuck. Ew!
Or maybe – worse – with no sense of history at all. No ability to ask “how did the world look like yesterday”, much less “3 months ago”. I’ve seen startups and presidential campaigns and 500 million dollar operations operate like this. 🙃
Now you know the secret. Now you have the magic. What mature companies have been doing all along: snapshot your data daily, append it with datestamps, and write idempotent pipelines on top.
That’s it. That’s the whole One Weird Trick. Add a ds column to every table. Filter on it. Write your pipelines to be independent of each other. Have every pipeline be ds-aware. Storage is cheap. Your time is expensive. Getting your data wrong is extra expensive.
What you get in return:
Backfills that run in parallel and finish in minutes instead of days
Backfills that are a button push instead of custom SQL mess.
Historical queries that are simple WHERE ds=’2024-10-01’ filters instead of date-range gymnastics
Pipelines that are the same whether you’re processing today or reprocessing last year
A built-in time machine for your entire warehouse
Bugs that are fixable instead of permanent scars on your data
This is functional data engineering. Functional as in idempotent. And functional as in “it works”.
Your backfills are easy now. Your 3am alerts will be rarer. Time complexity is solved. Data recovery is trivial. Your job just became so much easier.
Running and using a data warehouse can suck. There are pitfalls. It doesn’t have to be so hard. In fact, it can be so ridiculously easy that you’d be surprised people are paying you so much to do your data engineering job. My name is Sahar. I’m an old coworker of Zach’s from Facebook. This is our story. (Part two is here)
Data engineering can actually be easy, fast, and resilient! All you have to embrace is a simple concept:Date-stamping all your data.
Why isn’t this the norm? Because – even in 2025 — , institutions haven’t really understood the implications that STORAGE IS CHEAP! (And your data team’s time is expensive).
Datestamping solves so many problems. But you won’t find it in a standard textbook. They’ll teach you “slowly changing dimensions Type 2” when the real answer is simpler and more powerful. You will find the answer in Maxime Beauchemin’s seminal article on functional data engineering. Here’s the thing – I love Max, but that article is not helpful to the majority of people who could learn from it.
What if I told you:
We can have resilient pipelines.
We can master changes to data over time.
We can use One Weird Trick to marry the benefits of order and structure with the benefits of chaos and exploration.
That’s where this article comes in. It’s been 7 years in the making – all the stuff that you should know, but no one bothered to tell you yet. (At least, in plain english – sorry Max!)
Part One: How to set up a simple warehouse (and which small bits of jargon actually matter)
Part Two:Date-stamping. Understand this and everyone’s life will become easier, happier, and 90% more bug-free.
Part Three: Plugging metrics into AB testing. Warehousing enables experimentation. Experimentation enables business velocity.
Part Four: The limits of metrics and KPIs. It can be so captivating to chase short-term metrics to long-term doom.
I’ll show you a practical intro to scalable analytics warehousing, where date stamps are the organizing principle, not an afterthought. In plain language, not tied to any specific tool, and useful to you today Meta used this architecture even back in the early 2010s. It worked with Hive metastore. It still works with Iceberg, Delta, and Hudi.
But first, to understand why all this matters, you need some context about how warehouses work. Then I’ll show you the magic.
Part one — A Simple Explanation of Modern Data Warehousing
Our goals and our context
We are here to build a system that gets all company data, tidily, in one place. That allows us to make dashboards that executives and managers look at, charts and tools that analysts and product managers can use to do deep dives, alerts on anomalies, and a breadth of linked data that allows data scientists and researchers to look for magic or product insights. The basic building blocks are tables, and the pipelines that create and maintain them.
Sidebar: DB vs Data lake? OLTP vs OLAP? Production vs warehouse? Here’s what you need to know.
A basic point about a data warehouse (or lake, or pond, or whatever trendy buzzword people use today) is that it is not production. It must be a separate system from “the databases we use to power the product”.
Both are “databases”, both have “data”, including “tables” that might be similar or mirrored – but the similarity should end there.
Your production database is meant to be fast, serve your product and users. It is optimized for code to read and write.
Your warehouse is meant to be human-usable, and serve people inside the business. It is optimized for breadth, for use by human analysts, and to have historical records.
Put it this way – your ecommerce webapp needs to look up an item’s price and return it as fast as possible. Your warehouse needs to look up an item from a year ago, and look at how the price changed over the course of months. The database powering the webapp won’t even store the information, much less make it easy to compute. Meanwhile if you run a particularly difficult query, you don’t want your webapp to slow down.
Be reasonably up to date – with perhaps a daily lag, rather than a weekly or monthly one
Power charts and interactive tools, while also being useful for automatic and local queries
This used to be difficult! (It is not anymore!) There was a tradeoff between “big enough to have all the data we need” and “give answers fast enough to be useful”. A lot of hard work was put into reconciling those two needs.
Since circa 2015 or so, this pretty much no longer a problem. Presto/Trino, Spark, and hosted databases (BigQuery, Snowflake, the AWS offerings) and other tools allow you to have arbitrarily huge data, accessed quickly. We live in a golden age.
Sidebar: At my old school… At Meta, they used HDFS and Hive to power their data lake and MySQL to power production. Once a day they took a “snapshot” of production with a corresponding date stamp and moved the data from MySQL to Hive.
In a world where storage is cheap, access to data can be measured in seconds rather than minutes or hours, and data is overflowing, the bottleneck is engineering time and conceptual complexity. Solving that bottleneck allows us to break with annoyingly fiddly past best practices. That’s what I’m here to talk about.
A basic setup
Imagine your warehouse as a giant box, holding many, many tables. Think of data flowing downhill through it.
At the top: raw copies from production databases, marketing APIs, payment processors, whatever.
At the bottom: clean, trusted tables that analysts actually query.
In between: pipelines that flow data from table to table.
How do we get from raw input to clean tables? Pipelines. (See buzzwords like ETL, ELT? Ignore the froth – replace with “pipelines” and move on).
Pipelines are the #1 tool of data engineering. At their most basic form, they’re pieces of code that take in one or more input tables, do something to the data, and output a different table.
What language do you write pipelines in? Like it or not, the lingua franca of editing large-scale data is SQL. The lingua franca of accessing large scale data is SQL. SQL is a constrained enough language that it can parallelize easily. The tools that invisibly translate your simple snippets into complex mechanisms to grab data from different machines, transform it, join it, etc – they not only are literally set up with SQL in mind, they figuratively cannot do the same for python, java, etc. Why? Because a traditional programming language gives you too much flexibility — there’s no guarantee that your imperative code can be parallelized nicely.
Sidebar: When non-SQL makes sense (or doesn’t)
If you’re ingesting data from the outside world (calling APIs, reading streams, and so on), then python, javascript, etc could make sense. But once data is in the warehouse, beware anything that isn’t SQL – it’s likely unnecessary, and almost certainly going to be much slower than everything else.
Your tooling might offer a way to “backdoor” a bit of code (e.g. “write some java code that calls an API and then writes the resultant variable to a column”). Think twice before you use it. Often, it’s easier and faster to import a new dataset into your warehouse so that you can recreate with SQL joins what you would have done using an imperative language.
You may be tempted to transform or analyze data in R, pandas, or whatnot – that’s fine, but you do that by interactively reading from the warehouse. Rule of thumb: if you’re writing between tables in a warehouse – SQL. Into a warehouse – you probably need some glue code somewhere. Out of a warehouse – that’s on you.
So here’s the simple setup:
Each day, copy data into your warehouse. Copy in data from your production database, your marketing platform, your sales data, whatever. Don’t bother cleaning it as you pipe it over (ELT pattern NOT ETL!). Just do a straight copy, using whatever tools make sense
Then, set up a system of pipelines to this, every day, as soon as the upstream data is ready:
As each of these input tables gets the latest dump of data from outside: take that latest day’s data, deduplicate, clean it up a bit, rename the columns, and cascade it to a nicer, cleaner version of that table. (this is your silver tier data in medallion architecture)
Then, from that nicer input table, perform a host of transformations, joins, etc to write to other downstream tables. (this is your master data)
Master data is highly trusted which makes building metrics and powering dashboards easy!1
Every day, new data comes in, and your pipeline setup cascades new information in a host of tables downstream of it. That’s the setup.
A well-ordered table structure
Okay, so to review: the basic useful item in a warehouse is a table. Tables are created (and filled up by) pipelines.
“Great, great,” you might say – “but which tables do I build?”
For the sake of example, let’s imagine our product is a social network. But this typology should work just as well for whichever business you are in – from b2b saas to ecommerce to astrophysics.
From the perspective of the data warehouse as a product, there are only three kinds of tables: input tables (copied from outside), staging tables (used by pipelines and machines), and output tables – also known as user-facing tables.
Output tables (in fact, almost all tables) really only have three types:
Tables where each row corresponds to a noun. (E.g. “user”, or even “post” or “comment”). When done right, these are called dimension tables. Prefix their names with dim_
Tables where each row corresponds to an action. Think of them as fancier versions of logs. (E.g. “user X wrote post Y at time Z”). When done right, these are called fact tables. Prefix their names with fct_
Everything else. Often these will be summary tables. (e.g. “number of users who made at least 1 post, per country, per day). If you’re proud of these, prefix them with sum_ or agg_.
Sidebar: more on naming
YMMV, but I generally don’t prefix input tables. Input tables should be an exact copy of the table you’re importing from outside the warehouse. Changing names breaks that – and an unprefixed table name is a good sign that the table cannot be trusted.
Staging and temporary tables are prefixed with stg_ or tmp_.
Let’s talk more about dimension and fact tables, since they’re the core part of any clean warehouse.
Dimension tables are the clean, user-friendly, mature form of noun tables.
For instance, a dim_users table might both include stuff like: user id, date created, datetime last seen, number of friends, name; AND more aggregate “verby” information like: total number of posts written, comments made in the last 7 days, number of days active in the last month, number of views yesterday.
If a data analyst might consistently want that data – maybe add it to the table! Your small code tweak will save them hours of waiting a week.2
(Now, what’s to stop the table from being unusably wide? Say, with 500+ columns? Well, that’s mostly an internal culture problem, and somewhat a tooling problem. You could imagine, say, dim_user getting too large, so the more extraneous information is in a dim_user_extras table, to be joined in when necessary. Or using complex data types to reduce the number of columns)
Fact tables are the clean, user-friendly, mature form of logs (or actions or verb tables).
Despite being verb focused, fact tables contains noun information. (Zach chimes in: here’s a free 4 hour course on everything you need to know about fact tables)
Unlike a plain log, which will be terse, they can also be enriched with data that might probably live in a dim table.
The essence of a good fact table is providing all the necessary context to do analysis of the event in question.
A fact table, fundamentally, helps you understand: “Thing X happened at time Y. And here’s a bunch of context Z that you might enjoy”.
So a log containing “User Z made comment Xa on post Xb at time Y” could turn into a fct_comment table, with fields like: commenter id, comment id, post id, time, time at commenter timezone, comment text, post text, userid of owner of post, time zone of owner of parent post. Some of these fields are strictly speaking unnecessary – you could in theory do some joins to grab the post text, or the comment text, or time zone of the owner of the parent post. But they’re useful to have handy for your users, so why not save them time and grab them anyway.
Q: Wait – so if dim tables also have verb data, and fact tables also have noun data, what’s the difference?
A: Glad you asked. Here’s what it boils down to – is there one row per noun in the table? Dim. One row per “a thing happened?” Fact. That’s it. You’re welcome.
Here, as in so much, we are spending space freely. We are duplicating data. We are also doing a macro form of caching – rather than forcing users to join or group data on the fly, we have pipelines do it ahead of time.
Compute is cheap, storage is cheap. Staff time is not. We want analysis to be fluid and low latency – both technically in terms of compute, and in terms of mental overhead.
Q: Wait! What about data stamps? Where’s the magic? You promised magic.
A: Patience, young grasshopper. Part of enlightenment is the journey. Part of understanding the magic is understanding what it builds on. And – hey – would YOU read a huge blog post all at once? Or would you prefer to read it in chunks. Yeah, you with your Tiktok problem and inability to focus. I’m surprised you even made this far.
Explore the dream of functional data engineering (what is that weird phrase?)
Throw SCD-2 and other outdated “solutions” to the dustbin of history
For instance, join the data from your sales and marketing platforms to create a “customer” table. Or join various production tables to create a “user” table. Could you then combine “customer” and “user” to create a bigger table? You might add pipeline steps to create easy tables for analysts to use: “daily revenue grouped by country”, etc. ↩︎
Here’s another key insight: data processing done while everyone is asleep is much better than data querying done while people are on the clock and fighting a deadline ↩︎
Originally posted to fb; people seemed to like it. Saved here for posterity.
I am persian jewish. My family had lived in Iran for centuries, as far back as anyone remembered. Then both sets of my grandparents, independently, fled. One family fled in anticipation of the revolution. The other fled during it. In the last commercial flight to ever leave Tehran for Tel Aviv.
Being in Iran, my family saw and endured horrors. Friends dead in the streets. My family assaulted for being “dirty jews”.
Leaving Iran, my family had to endure horrors. I know I still don’t know the extent of it — even a few years ago I learned some shocking stories.
Years ago, in 2009, there was a huge protest wave in Iran. I remember being glued to twitter at the time, keeping up with videos and commentators and so on.
And, at one moment, I had such a vivid punch in the gut. I know myself. I know my personality. If I were there, I would have taken to the streets, and posted things excitedly but unwisely. I’d have been picked up by the secret police, tortured, and killed. It was really clear to me — if I was in Iran, if I had survived up till then, I would have gotten carried away by events and died that summer of 2009.
Right now, I’m thinking of the Iranian people, again, nonviolently marching for democracy, freedom, and all that. And, more than ever, they’re being brutally gunned down by the regime. Thousands and thousands of people shot in the head for calling for democracy and and end to the theocratic police state.
If I had survived up till that point, would I have marched too? Would I have posted something ill-advised? Would there be the torturers knock on my door? Or, if I had stayed alive til then, maybe I would by definition have learned to keep my mouth shut?
I’ve got nothing on the personal, physical bravery of the Iranian people. I have tremendous respect for them. And I am thinking of all my Iranian/Persian friends today, who likely have friends and family in the line of fire.
A few years ago, there was another abortive protest wave, also brutally crushed. I was at a fellowship retreat in New York, and a few persian fellows and I skipped out and marched in Manhattan. It was funny, seeing a protest march run by people who were not steeped in lefty protest/activist culture. A little uncanny valley. And really, really, wholesome.
One day, I dream of being able to visit the streets, cities, and homes of my ancestors without being shot in the head. I dream of a world where people learn the right lessons from the Iranian Islamic Revolution. And I dream that this new revolution succeeds.
Every once in a while I update my “Now. page”. I try to keep track of how it changes over time — when I do make big changes. (Small tweaks? Not worth a post.)
Here, I’ll show what it’s been updated to, and updated from.
The new, October 2025 version of the Now page looks like this:
Big picture: Omri was born this spring. Sarah is healthy after an extra-hard pregnancy. He’s in daycare now, which means I have time to build things for fun and be thoughtful about what’s next professionally.
What I’m building:
Bespoke apps for Sarah’s work (LLM-assisted coding is a gamechanger for speed and fun).
I’ve been rereading Terry Pratchett with fresh eyes – getting so much more out of it critically than the last time through.
What I’m playing and watching:
Gloomhaven and Frosthaven with Sarah. Started a local dads Gloomhaven group. Started a weekly gloomhaven game with a friend (and his girlfriend, and Sarah).
During Sarah’s pregnancy I had irregular snatches of time – used them to revisit Psychonauts 1 & 2 (deeper and wiser than I thought), XCOM, and others.
We’ve been (re) watching the Wire. Sarah has never seen it. It’s hitting much harder for me than it did in early college.
I’ve been cooling on Dropout, but it’s still a good source of fun.
Finally broke down and paid for a subscription to War on the Rocks. Hey, it beats twitter!
Before that, we went glamping upstate for cousin Matan’s wedding.
Before that, we flew to Colorado for Sarah’s cousin’s wedding. (That was tough. Flying + time zones + lack of good eating + elevation created a very cranky baby).
Misha got married too! Sad I missed that one. But she seems lovely.
Day to day:
Walking in Brooklyn Botanic Garden (solo and with Sarah and Omri).
Climbing again. Being present in group chats. Going to weddings.
Started the Artist’s Way again, paused it because the pregnancy got too intense.
We’re throwing shabbat dinners, a passover seder, and so on.
Hosting game nights (often organized by others — hosting means we can hang with people after Omri falls asleep)
Work:
I’m looking for my next role.
Ideally something that lets me build 0→1, work across teams, and teach/enable others.
With kind, competent people.
Think Special Projects, Developer Relations, Engineering Manager, or strategic IC (SWE/DE/FDE/PE).
Especially interested in AI companies, dev tools.
Or, honestly, places where I can learn more about how the economy (and the business) works.
If you know a fit, or just want to chat about possibilities: hit me up!
The old, March 2025 version of the Now page used to look like this:
Last updated: March 20, 2025
Woombie is coming. I’m preparing to be a dad. Sarah’s pregnancy is filled with complications and tougher than most. I’m spending a lot of energy helping her.
Family has visited a few times. We’re cleaning up the apartment and buying objects for the baby. We threw “Woombie’s early 0th birthday party” as an alternative baby shower. Many friends showed up, it was delightful.
I’ve been writing a bit more. Mostly it stays in drafts. I’ve been taking up martial arts, and lifting a bit again. Spring has come, and I’m walking outside more.
For years, I’ve noticed that I’m re-reading the same books over and over again as a sort of comfort blanket. Lately, I’ve branched out and am reading new (to me) fiction again. It’s delightful.
It’s hard for Sarah to eat pretty much anything. We just made ~20 pounds of goat stew for her, which was a fun little project. We’ll probably have to make more soon.
I’m thinking about what kind of job I want next. What role: IC? Manager? Executive? What type of skills: software, product management, something else? What type of industry?
Over the last few months I’ve gotten to know my neighbors — and neighborhood — quite a lot better. Feeling more rooted. Happier. Sarah and I play a lot of Gloomhaven and watch game shows. I sing songs to Woombie and wonder if he can hear them.
I’ve detoxed from twitter almost completely. It’s not on my phone. My methadone is reddit, but it kind of sucks. Whereas twitter helps me think but makes me angry, reddit annoys me and makes me feel dumber. Theoretically substack/newsletters are the answer, but it doesn’t hit the same for some reason.
I like being a dad. I think I’m good at it. And I think Omri is really great.
I notice different things. My friends are mostly childless and it’s strange to move in the world differently than them.
I notice whether bathrooms have changing tables now.
I look for kids and parents when I’m out and about, and smile at them when I do. If Omri is there — they light up. If not, they often don’t realize what’s up and don’t smile back.
Any time longer than 1 hour to focus on a task is precious.
Any time the baby is in the room, and I’m not looking at him and interacting with him, I feel bad.
The thought of traveling is much more daunting.
A casual night out went from “oh we can get $15 tickets to the event and subway there” turns into “wow, we have One Night free. We need to pay the babysitter $$$, so we might as well take a taxi to minimize travel time.”
The baby makes me softer and happier. Less angry. Less in-the-news, more in-the-room. Just a bit, for now.
I like how he looks at me. It makes me want to be a better person.
It’s just getting started. I can tell (I can guess?) I will feel things like this, but stronger — and other changes I can’t predict — when he’s just a little older.
Over the last few years, I appeared on many podcasts. And some panels or speeches I gave were recorded. So many that I lost track — I was busy running a think tank!
Perhaps just for my own use, here’s a partial list of places I’ve been. Podcasts, and also recorded panels and so on. I am sure I missed a few! (Especially panels). When I find them, I’ll update.
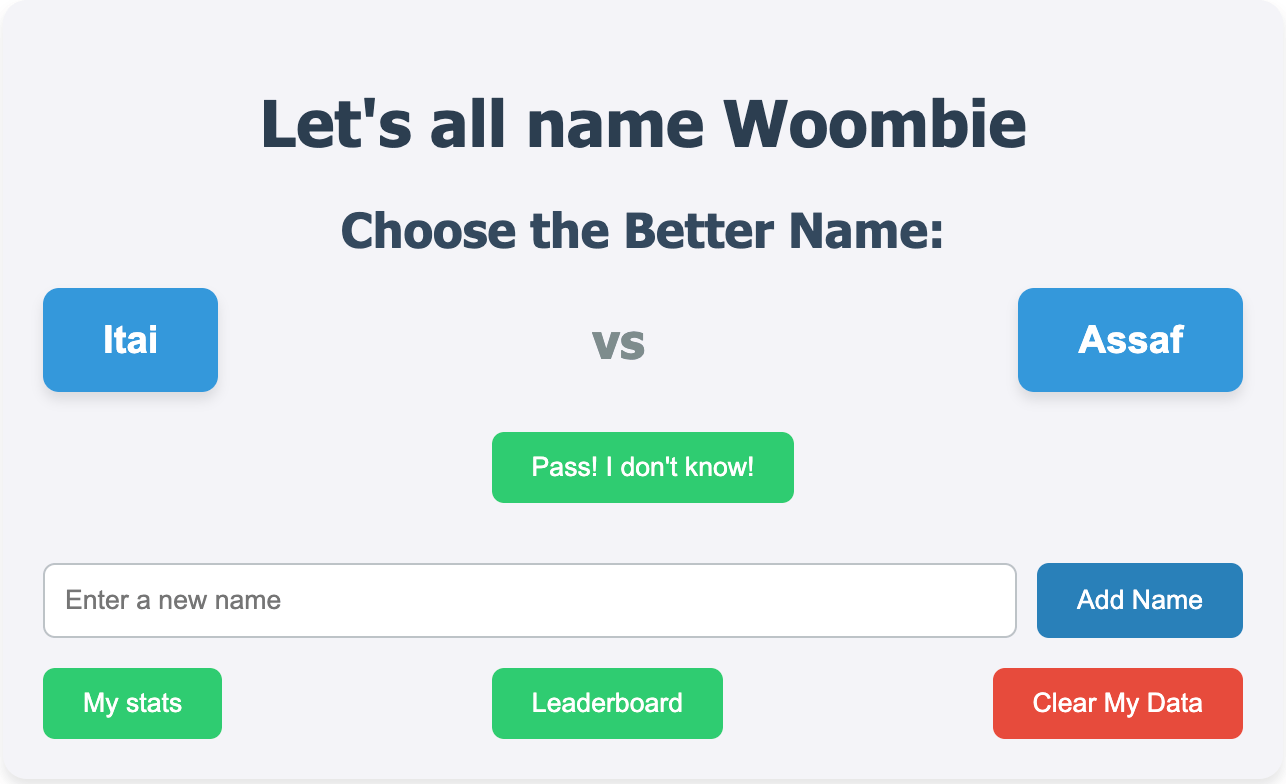
The other day, I had a problem. Wombie was coming soon, but we still didn’t have a name picked out of the baby-to-be! Or, rather, we didn’t have a sense of 3ish names we most liked (so that we could see which fit him best at the hospital).
There were some strong contenders (Omri, Amit, Amitai, Alon) that were sort of tied for us. But maybe if we used the power of statistics, we’d find out that one was secretly stronger than the others as expressed by our votes?
This quickly spun out of control. I created a new version for family to vote for. Then another, public version for friends at large to vote.
Meanwhile, I was hard at work on creating a leaderboard. And it led to some challenges!
The first few decisions were relatively simple:
Simple vote counting didn’t work well. If my mom voted for X over Y over and over again, then that should flatten out to one vote for X over Y, right? Easy enough.
But what if someone voted for name X over Y 3 times, but Y over X 1 time? Does X get 3/4 of a vote? A full vote?
How do we represent the leaderboard? Aren’t there algorithms to figure out winners of pairwise matchups? I hear Elo is good…
But then it got complicated.
First off, user submitted names really mucked things up:
People submitted some names that I liked, some names I disliked, and some names that were clearly trolling.
If I didn’t propagate the names to other voters for consideration, then the point of submission was lost. But then junk names kept polluting the voting.
I had to invent a coefficient to allow user-submitted names to propagate, but slower than hardcoded names.
I also had to implement a blocklist for troll names.
If someone submitted a name and kept voting for it, that name would get a perfect win/loss record until it propagated
And it turns out that finding the “true” winner of pairwise unordered matchups by judges who judged a highly variable number of matchups each — is weirdly complex.
Heavy is the head the chooses the crown:
Bad or trollish user-submitted names kept dominating the rankings. As a backstop, I implemented two filters: filter out names with only one voter voting for them, and just filter out user-submitted names totally.
Turns out the Elo rankings care about order because they model candidate names as players who could change in skill over time. Oops! Out with Elo
I thought about my Integrity Institute days and the mighty power of PageRank. If a candidate name was a domain, and losing to another name was a “link” to that name, we could model a bootstrapped way to find network centrality with untrusted actors!
Some searching found Bradley-Terry rankings. Apparently they’re made for unordered pairwise matches?
I tried on Eigenvector Centrality (though, honestly, I don’t quite understand it) as a generalized variant of PageRank.
And, despite all the fancy stats, I realized that I needed simple win/loss ratios just to sanity check!
And here’s how I made it, technically:
Val.town is an amazing platform for focusing on prototyping an app rather than worrying about tooling, deployment, etc. Big fan!
I used a lot of LLM help! First, ValTown’s in-house “Townie” app. Then Cursor.
LLM’s are kinda dumb. I had to keep rescuing it from mistakes. But fun! Turns out I was semi vibe coding before I knew what it was.
I used Cursor to help think through different statistical methods. But I was careful about errors in implementation. I actually had a python code test suite for the data, and also a javascript one. I figured that python code would be more canonical for the LLM, and more likely to be a true implementation of the concept (and I kept prodding it for that to be true). Then I could check the fidelity of the javascript (which is the language of ValTown) to the python test suite
As I made the app more and more complex (better logging! Usernames and user stats) I had to create a separate admin panel app just to spot check and edit data, upgrade from v1 of logging structures to v2, etc.
Each algorithm showed different winners. The private, family version found different winners than public.
As the README puts it:
This is also an exploration and tutorial in the world of ranking and statistics. Specifically —
With messy or imperfect data, even algorithms meant to account for it give different results
The power of regularization. Throw out a few rogue actors / outlier data and things become a lot clearer
Rather than put data into a black box algorithm and call it a day: interrogate the results!
And
Data is important, analyzing it is helpful, data sense to interrogate the problem is necessary — but at the end of the day, making decisions needs to be informed by data, not mandated.
In the end, Sarah and I spent the first four days in the hospital looking at the little baby, thinking about what he looked like, and also what kind of expectations we wanted to put on him. What name would work well for a child as well as a man? We made our choice based on instinct and reason — but not before I peeked at the leaderboard to make sure that Omri was among the best performers.
Years ago, I watched a strange phenomenon unfold at a company where I knew someone on the inside.
The CEO made some bizarrely destructive calls that, frankly, undermined the entire organization. Powerful investors were upset. So upset that you might imagine that they would punish that CEO. Then that CEO went to them and asked for more money, on extremely generous (to him) terms. He got it.
Why did big screwups from the leader cause increased funding? It stems from a concept I’m calling Chaos Budgeting.
First, the obvious core idea: Every organization (as large as a country, as small as a household) has a balance sheet. That balance sheet has tangible assets, but also intangibles like morale, brand positioning, etc. One of the important intangible assets it has is stability (or its antonym, chaos).
And now, the surprising corollary: an organization can only take so much upheaval. If someone ramps up the chaos so that the budget is maxed out, their opponents can’t spend it — even to hold them accountable in the short term.
The organization was so unsettled — so chaotic — that those with a stake in it felt bound to tamp down on it and increase stability, even if that meant rewarding the person causing that chaos. Why did they have a stake in it? Because it was working on an important, time sensitive mission where failure would cause ripple effects across the landscape. It was too important to fail.
If your stability/chaos budget is spent, you can’t spend it to hold people accountable.
I think we can see this dynamic around us in surprising ways. In 2016, the country as a whole was open (maybe eager) for some chaos. Trump won. By 2020, though, we had a ton more on our balance sheet. Covid! Norms! Impeachment! A lawless executive. And the country was yearning for more stability. Not only did that help Biden win the general, it explains why Bernie lost the primary. His campaign was talking about expansive executive orders, litigating their proposed laws in the supreme court — chaos, in order to overturn “corrupt establishment politics”. Primary voters made the determination that the country could no longer afford that brinksmanship; he lost.
This helps explain why terrible people at work can’t be forced out, or why bad CEOs get severance packages and salutes rather than their dirty laundry spilled.
It explains why relatives who cause drama and act hostile keep getting invited to family gatherings — their bad behavior is priced in. But kicking them out would cause too much short-term chaos debt.
Now, this isn’t a huge insight, nor is it One Weird Trick to always get your way. That organization I was following? When things settled down, investors were able to derisk their support and make it no longer Too Important To Fail.
What does this mean for navigating groups as a founder, staffer, investor, volunteer, or citizen? I’m not sure. I have a few small ideas, but I’m still chewing on it.
Don’t ever max out your chaos budget — because then accountability gets screwy.
When people avoid creating ‘thrash,’ they might be protecting the organization’s stability reserves
There’s a tragedy of the commons here: multiple actors competing to spend the same chaos budget. Unclear if you should dive in yourself or try to find a way to solve the tragedy.
When you see people in the news break things destructively, maybe this is part of their plan.
I don’t know. I bet there are bigger, more important insights to be had here. Let’s keep thinking about it.
It’s time to go public: I’m (probably, b’ezrat hashem) going to be a dad. And soon.
The baby-to-be’s placeholder name is Woombie. (He’s the brother of our robot vacuum named Roombie).
We’re thinking of names now. I’m looking for something that, like my name, is plausible both in hebrew and farsi, and doesn’t sound terrible in english.
Mom and dad (and Sarah’s mom and dad, separately) came and upgraded the apartment a few weeks ago. We got a crib, a bed, and objects. We generally dealt with the fact that the majority of my possessions, by weight, are books — new shelves, threw some old novels out, and re-arranged furniture. Lead-proofed the water.
Being a parent-to-be is hard. Nerve-wracking. So many books to read. So many decisions to make. They tell you to store up sleep — at least I can do that easily.
I like how we’re doing it, though. Sarah and I spend a lot of time in the evening playing board games together. We get excited about what we’d be like as parents. I’m collecting old children’s television shows and books for Wombie. Many people tell me I’d be a great dad. That’s nice.
It’s been tough for Sarah. Her pregnancy complications are pretty intense. She’s limited and pained in a way that is not normal, even for a pregnancy. Much of my time and energy is used taking care of her. On the more prosaic side — she’s gotten really big. She misses rock climbing a lot. I miss it too. The winter, and baby stuff, really has pushed me indoors.
We’re trying to be intentional on what we keep chill on. We don’t want to make a big deal about the sex or gender of the child (a boy). We aren’t having a baby shower or traditional registry, but we are having a “Woombie’s first birthday party” and making our “to buy/acquire” google sheet quasi-public.
We’re part of a parent’s group (a real community organization!) that sets people up in cohorts. (So we’re in the “April 2025 parents”, for example). Of the many, many, couples that introduced themselves in the intro thread, I think I was the only guy to be the ambassador for theirs.
They say children are a great way to manufacture meaning in life. I hope that’s true. I’m worried for Sarah. She’s going through a lot. This is not normal.
But we only have a little while left! And I’m so glad to enter the mysterious social world of parents. PTA meetings, thumbs up at each other’s strollers, walking around the Botanic garden with a baby strapped to me — that sounds so fun. Let’s go.
Ask you to help us find people who would love it and use it.
Give you a bit of behind-the-scenes context
Before I get into it, I want to say that our projected user might very well not be you! But I still need your help. I bet there are people (or organizations) in your life that would love it. Please help us get it to them.
I remember reading once that Aaron Swartz independently invented wikipedia when he was a literal child. Years before Jimmy Wales. But Aaron was a kid! So his version had articles about magic cards written by his 10-year-old friends. He had great vision for a product, then built it, but his userbase never left his immediate friends. I don’t want to fall into that trap.
Most voters get their news via social media, specifically video, and often first directed by chat threads
Those platforms select content based on engagement, not on quality, and definitely not on what will help persuade voters to vote for democrats
Normal people can make a big difference in the election by elevating the most persuasive content and arguments
Or, to put it another way: I, like many other americans, spend much of my life online. I bet you do too. It’s where I talk to strangers, family, and friends. It makes sense that online is a place where persuasion has impact, for good or ill.
So we made a playbook for how exactly to do it smarter than “post everything that makes you angry to Facebook/twitter and hope for the best”. It’s a combination of our expertise in integrity work, plus my time in 2020, campaigns, and so on. I think it’s quite goo!
We built a (fun?) companion app full of tiktoks/tweets/articles/content that IS persuasive with swing voters —
For sharing
For inspiration
For specifically inspiring people to make similar videos/tiktoks/tweets/posts
(And there’s more coming!)
Enjoy! But also — please spread
I hope you’ll do two things, please:
If you find this useful yourself — dope! Great! Dive in.
This may not be for you — but I BET you know some people who would love this. Organizations? Resistance facebook groups? Very online moms and dads? Please help me find the people who would love this
…But you don’t have to take my word for it
In the time it took me to write this — we got the Matthew Yglesias endorsement.
We’ve also got big orgs reach out and want to talk about partnering. And smaller grassroots groups telling me they’re already using it. Hooray!
So, uh, things are good!
I can say more about the theoretical underpinnings of all this, if you want. But then again, the guide is pretty long, maybe just read it! And if you have any questions, let me know.
In 2020, a friend of mine (Lyla) and Sarah I set up a fundraiser for the election. Part of that was giving people a guide of where to give. We raised $84,123 to the following recipients. Now, I’m giving my 2024 guide of how to donate for all the elections.It’s written as a memo because it originally was one! I sent it to a friend of mine who tithes 10% of their income to good works.
A memo for friends.
This is about how to spend money wisely. Here’s how we can think about it:
The less sexy the race, (the farther away from federal/presidential), the higher the impact and the higher the relative impact
Control of states is incredibly important
State Supreme Courts are unsexy, powerful, not financed well
While House races are high up (aka sexy and maybe relatively well funded), control of the House is very important to protect america in case Trump wins (and probably takes the Senate)
While targeting money well is helpful, it’s easy to over-concern yourself with it. Donate directly to candidates and you’ll generally be fine.
Due to how some laws work, it’s better bang-for-the-buck to donate directly to candidates than to PACs
I suggest splitting your money in the following ways, in descending order of importance:
State Supreme Court races
AZ County Recorder
Key state legislature races
(Bonus): US House
State Supreme Court races are the ones I’m most excited by. Huge important races that might swing control, often underfunded and looked over.
The AZ Maricopa county recorder oversees elections for (by far) biggest county in Arizona — a key state and one where election deniers are particularly fierce
These state Leg races might swing control of key chambers.
Given ~10k, here’s how I would split it:
$1580 (the maximum) for two Montana state supreme court races.
$4500 split 6 ways for six other state supreme court races.
$500 for Maricopa County Recorder
$3500 split 8 ways for 8 state leg races
That comes out to $10,080.
Alternative/bonus: If you want to shift more towards the urgent task of preventing unified Republican control of government eroding our democracy — I suggest the US House. That’s also in the appendix.